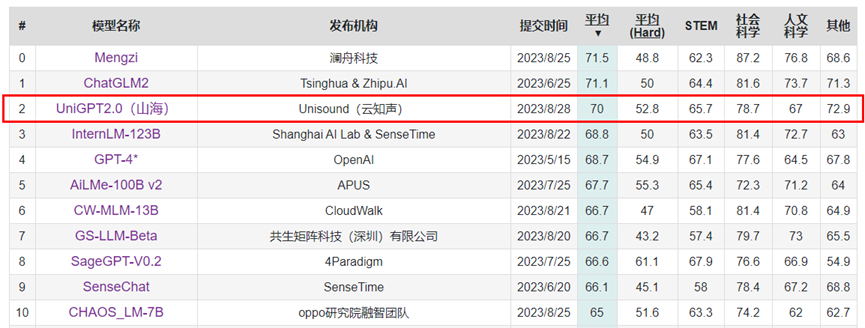
8月28日,山海大模型迎来又一次迭代升级,当前版本参数规模达到千亿,实现了多学科能力、医疗能力双提升,实测性能在C-Eval全球大模型综合性评测中超越GPT-4,以平均分70分的成绩进入前三甲。
能力突破,持续领跑行业
●多学科能力增强
本次山海大模型2.0版参数规模达到千亿,增加了更多的学科类的预训练语料,训练数据(Tokens)达到两万亿(2.0T)。
在本次模型升级过程中,山海团队充分利用了教材、文献、百科类语料的价值,这些语料包含了人类对客观世界知识的丰富理解、详尽解释以及在各个领域的深入研究所得到的科学结论。不同的学科领域的数据涵盖了各自学科的专业知识,这在一定程度上弥补了第一版山海大模型在某些专业领域的知识盲区。
为了使模型能更科学合理地汲取这些不同领域和来源的数据中的知识,山海大模型团队使用了DoReMi方法对数据进行了优化权重采样。通过这种策略,可以在较大范围内均匀并深入地提取各类信息。这一策略使得山海团队在本次模型升级过程中,能更有效地吸取和运用各种知识,使模型的知识库更加全面。

●医疗能力再升级
云知声深耕医学领域多年,山海大模型2.0在预训练阶段使用了海量的医学病历、医学教材、临床指南和医学文献等数据,并在对齐阶段使用了人机结合方法构建的近百万级的病历理解、医学考试和医学知识问答等指令学习数据。C-Eval中医疗学科的结果表明,山海大模型2.0在基础医学、临床医学和医师资格数据集上都能获得接近90分的水平,为业内最高。

云知声山海大模型团队参加了刚刚在沈阳结束的CCKS2023-PromptCBLUE评测,该评测是当前最权威的中文医疗大模型的评测榜单,我们同样也取得了第一名的成绩,再次证明了山海大模型专业的医学能力。

技术升级,性能加速提升
●窗口长度大幅度扩展
山海团队发现,在运用位置插值(Position Interpolation)方法进行大幅度扩展时——比如将窗口从4k扩展到32k——其性能会显著受到影响。这种影响主要体现在短距离情况下的使用。为了更好地解释这一点,假设原始数据中距离为1的两个token,当我们将数据从4k扩展到32k时,这两个token之间的距离实际上变成了1/8。这就意味着,在进行位置插值的过程中,原本距离很近的两个token之间的距离被大比例地拉远了。这种场景下,衰减规律在短距离的使用会受到较大的影响,这是因为衰减规律在短距离时可能具有非常突出的变化率,意味着原本应该很近的两个token在大规模扩展之后,它们之间的关联性会大幅度减小。因此,直接进行位置插值的方法会使得窗口大幅度扩展后的性能较大程度地降低。发现RoPE位置编码短距离之间的差异,主要体现在高频分量上,长距离之间的差异,主要体现在低频分量上。山海大模型2.0版根据神经正切核的思想,采用Neural Tangent Kernel (NTK)的非线性差值方法,实现高频外推、低频内插的大规模长度扩展。采用NTK扩展后模型能够更好的支持文本窗口扩展,当前山海大模型2.0版本已经支持32K的窗口长度。
●受限解码支持业务落地
在大多数行业中,对大模型的并发使用和响应时间有很高的要求。这要求我们在保证大模型算法效果的基础上,更需要深思其推理速度。本次山海大模型2.0基于落地场景需要,设计了受限解码方法,在解码过程中不需要计算整个词表的概率,只需关注落地场景下关注的token,极大地提高了解码效率。如图所示,利用受限解码方法,生成token“今”后面只需考虑token“夕”和“天”的概率,而不需要完成整个词表概率分布的计算。

作为中国AGI技术产业化的先驱之一,云知声于2016年开始打造Atlas人工智能基础设施,并以此为基础,构建云知大脑(UniBrain)技术中台——以山海(UniGPT)通用认知大模型为核心,结合多模态感知与生成、知识图谱、物联平台等智能组件,为云知声智慧物联、智慧医疗等业务提供高效的产品化支撑,持续推动“U(云知大脑)+X(应用场景)”战略布局,践行“通过通用人工智能(AGI)创建互联直觉的世界”的公司使命。
云知声:通过通用人工智能(AGI)创建互联直觉的世界

云知声AI技术体系及U+X战略
山海大模型作为云知大脑的核心,能力体系涵盖语言生成、语言理解、知识问答、 逻辑推理、代码能力、数学能力等。此外,为提高大模型在具体场景的应用落地水平,山海大模型在通用能力基础上,增强物联、医疗等行业能力,致力为客户提供更智能、更灵活的解决方案,加速千行百业的智慧化升级。
自5月24日发布以来,山海大模型始终保持高速演进,不断拓展大模型场景应用边界——
●6月25日,山海大模型通过迭代实现了在特定领域内的专业知识积累,诗词创作能力、数学计算能力实现突破。其中,医疗能力在6月的MedQA任务上提升到了87.1%,超越Med-PaLM 2,临床执业医师资格考试提升至523(总分600分),超过了99%的考生水平。
●6月27日。北京市首批10个人工智能行业大模型应用案例公布,由云知声和北京友谊医院共同开发的基于山海大模型的门诊病历生成系统示范应用成功入选。
●7月2日,凭借山海大模型卓越的研发和应用成果,云知声同时入选2023北京人工智能行业赋能典型案例、“北京市通用人工智能产业创新伙伴计划”第二批成员名单。
●7月6日-8日,云知声携山海大模型及最新场景应用——基于山海大模型打造的智慧车载解决方案、智慧交通解决方案亮相2023 WAIC。
●7月28日,山海大模型迎来新一轮迭代升级,并在本月的C-Eval全球大模型综合性考试评测中取得了60分以上的优异成绩,成功跻身榜单前十。
●8月27日,CCKS 2023现场公布系列评测任务结果,云知声凭借基于山海大模型孵化的UNIGPT-MED 模型,在PromptCBLUE医疗大模型评测中夺得A、B榜双榜冠军。
云知声希望,通过山海大模型的持续升级,不仅打造基础能力更加强大的通用大模型,也进一步融合不同垂直领域的专业知识,让大模型更懂行业、更具专长,实现大模型应用场景的加速拓展,让大模型的产业价值在千行百业中绽放。
此次云知声跻身C-Eval全球大模型综合性考试评测前三甲,再一次印证了山海大模型的突出实力,也将持续推动云知声AGI基础设施能力的跃进提升,加速人工智能技术的创新与应用。未来,云知声将以其强大的技术实力、不断创新的科研能力以及对人工智能发展的深刻理解,不断构建长期竞争力和创新基石,持续探索AGI的无限可能。
附:C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,包含13948道多项选择题,涵盖数学、物理、化学、生物、历史、政治、计算机等52个不同学科和四个难度级别,是全球最具影响力的综合性考试评测集之一。作为第三方发起的测试基准, C-Eval以其客观性、公正性备受业内关注,也吸引了多家企业、机构和高校的参与。




















